%20--%3e%3csvg%20version='1.1'%20xmlns='http://www.w3.org/2000/svg'%20x='0px'%20y='0px'%20viewBox='0%200%20207.3%2029'%20style='enable-background:new%200%200%20207.3%2029;'%20xml:space='preserve'%3e%3cstyle%20type='text/css'%3e%20.st0{fill:%231E293B;}%20.st1{fill:%232563eb;}%20%3c/style%3e%3cg%20id='Ebene_1'%3e%3cg%20id='Ebene_2_00000023959154727838081460000010218683892316788135_'%3e%3cg%3e%3cg%3e%3cpath%20class='st0'%20d='M24.3,7.4c0-0.8,0-1.5,0-2.2c0-0.6-0.4-1-1-1c-4.4,0-7.6-1.2-10.4-3.9c-0.4-0.3-1-0.3-1.5,0%20C8.7,2.9,5.4,4.1,1.1,4.1c-0.6,0-1,0.5-1,1c0,0.7,0,1.5,0,2.2c-0.2,7.4-0.4,17.3,11.8,21.6l0.3,0.1l0.3-0.1%20C24.6,24.6,24.4,14.7,24.3,7.4z%20M11.4,17.5C11.4,17.5,11.3,17.5,11.4,17.5c-0.3,0.2-0.5,0.3-0.8,0.3l0,0c-0.3,0-0.5-0.2-0.7-0.3%20l-2.7-3c-0.3-0.3-0.3-0.9,0.1-1.1L7.5,13c0.3-0.3,0.9-0.3,1.1,0.1l1.4,1.6c0.3,0.3,0.8,0.3,1.1,0.1l4.4-4.2%20c0.3-0.3,0.9-0.3,1.1,0l0.3,0.3c0.3,0.3,0.3,0.9,0,1.1L11.4,17.5z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg%20id='Ebene_2'%3e%3cg%3e%3cpath%20class='st1'%20d='M46.3,8.6h-5.1v14.1h-2.8V8.6h-5.1V6.2h13V8.6z'/%3e%3cpath%20class='st1'%20d='M54.3,16.2h-3.2v6.3h-2.8V6.2h5.8c1.9,0,3.3,0.4,4.4,1.3S60,9.6,60,11.2c0,1.1-0.3,2-0.8,2.8%20c-0.5,0.7-1.3,1.3-2.2,1.7l3.7,6.8v0.2h-3L54.3,16.2z%20M51.1,13.9H54c1,0,1.7-0.2,2.2-0.7s0.8-1.1,0.8-2s-0.2-1.5-0.8-2%20C55.7,8.7,55,8.5,54,8.5h-3v5.4H51.1z'/%3e%3cpath%20class='st1'%20d='M74.3,6.2v10.9c0,1.7-0.6,3.1-1.7,4.1s-2.6,1.5-4.4,1.5c-1.9,0-3.4-0.5-4.5-1.5c-1.1-1-1.6-2.3-1.6-4.1V6.2%20h2.8v10.9c0,1.1,0.3,1.9,0.8,2.5c0.5,0.6,1.4,0.9,2.5,0.9c2.2,0,3.3-1.1,3.3-3.5V6.2H74.3z'/%3e%3cpath%20class='st1'%20d='M85.7,18.3c0-0.7-0.2-1.3-0.8-1.7c-0.5-0.4-1.4-0.8-2.7-1.2c-1.3-0.4-2.4-0.8-3.1-1.3%20c-1.5-0.9-2.2-2.2-2.2-3.7c0-1.3,0.5-2.4,1.6-3.3s2.5-1.3,4.2-1.3c1.1,0,2.2,0.2,3,0.6c0.8,0.4,1.6,1,2.1,1.8s0.8,1.6,0.8,2.6%20h-2.8c0-0.9-0.3-1.5-0.8-2s-1.3-0.7-2.3-0.7c-0.9,0-1.7,0.2-2.2,0.6s-0.8,1-0.8,1.7c0,0.6,0.3,1.1,0.8,1.5s1.5,0.8,2.7,1.2%20c1.2,0.4,2.3,0.8,3.1,1.3c0.8,0.5,1.3,1,1.7,1.7c0.4,0.6,0.5,1.4,0.5,2.2c0,1.4-0.5,2.5-1.6,3.2c-1,0.8-2.5,1.2-4.2,1.2%20c-1.2,0-2.3-0.2-3.3-0.7c-1-0.4-1.8-1-2.3-1.8s-0.8-1.7-0.8-2.7h2.8c0,0.9,0.3,1.6,0.9,2.2c0.6,0.6,1.5,0.8,2.6,0.8%20c1,0,1.7-0.2,2.2-0.6C85.4,19.5,85.7,19,85.7,18.3z'/%3e%3cpath%20class='st1'%20d='M102.6,8.6h-5.1v14.1h-2.8V8.6h-5.1V6.2h13V8.6z'/%3e%3cpath%20class='st0'%20d='M117,17.2c-0.2,1.7-0.8,3.1-1.9,4.1s-2.6,1.5-4.5,1.5c-1.3,0-2.4-0.3-3.4-0.9c-1-0.6-1.8-1.5-2.3-2.6%20c-0.5-1.1-0.8-2.5-0.8-4v-1.5c0-1.5,0.3-2.9,0.8-4.1s1.3-2.1,2.3-2.7s2.2-0.9,3.5-0.9c1.8,0,3.3,0.5,4.4,1.5s1.7,2.4,1.9,4.1h-2.8%20c-0.1-1.2-0.5-2-1-2.5c-0.6-0.5-1.4-0.8-2.4-0.8c-1.2,0-2.2,0.5-2.8,1.4c-0.7,0.9-1,2.2-1,4v1.5c0,1.8,0.3,3.1,0.9,4.1%20s1.6,1.4,2.8,1.4c1.1,0,1.9-0.2,2.5-0.8c0.6-0.5,0.9-1.3,1.1-2.5L117,17.2L117,17.2z'/%3e%3cpath%20class='st0'%20d='M128.5,18.8h-6.4l-1.3,3.8h-2.9l6.2-16.4h2.6l6.2,16.4h-3L128.5,18.8z%20M122.9,16.5h4.7l-2.4-6.8L122.9,16.5z'%20/%3e%3cpath%20class='st0'%20d='M137.2,16.5v6.1h-2.8V6.2h6.3c1.8,0,3.3,0.5,4.3,1.4c1.1,1,1.6,2.2,1.6,3.8c0,1.6-0.5,2.9-1.6,3.7%20c-1.1,0.8-2.5,1.3-4.4,1.3C140.6,16.4,137.2,16.4,137.2,16.5z%20M137.2,14.2h3.4c1,0,1.8-0.2,2.3-0.7s0.8-1.2,0.8-2.1%20s-0.3-1.6-0.8-2.1s-1.3-0.8-2.2-0.8h-3.5C137.2,8.6,137.2,14.2,137.2,14.2z'/%3e%3cpath%20class='st0'%20d='M160.7,8.6h-5.1v14.1h-2.8V8.6h-5.1V6.2h13V8.6L160.7,8.6z'/%3e%3cpath%20class='st0'%20d='M175.1,17.2c-0.2,1.7-0.8,3.1-1.9,4.1c-1.1,1-2.6,1.5-4.5,1.5c-1.3,0-2.4-0.3-3.4-0.9c-1-0.6-1.8-1.5-2.3-2.6%20c-0.5-1.1-0.8-2.5-0.8-4v-1.5c0-1.5,0.3-2.9,0.8-4.1s1.3-2.1,2.4-2.7c1-0.6,2.2-0.9,3.5-0.9c1.8,0,3.3,0.5,4.4,1.5%20s1.7,2.4,1.9,4.1h-2.8c-0.1-1.2-0.5-2-1-2.5S170,8.4,169,8.4c-1.2,0-2.2,0.5-2.9,1.4s-1,2.2-1,4v1.5c0,1.8,0.3,3.1,0.9,4.1%20c0.6,0.9,1.6,1.4,2.8,1.4c1.1,0,1.9-0.2,2.5-0.8c0.6-0.5,0.9-1.3,1.1-2.5L175.1,17.2L175.1,17.2z'/%3e%3cpath%20class='st0'%20d='M190.4,22.5h-2.8v-7.2h-7.3v7.2h-2.8V6.2h2.8v6.8h7.3V6.2h2.8V22.5z'/%3e%3cpath%20class='st0'%20d='M202.8,18.8h-6.3l-1.3,3.8h-2.9l6.2-16.4h2.6l6.2,16.4h-3L202.8,18.8z%20M197.3,16.5h4.7l-2.4-6.8L197.3,16.5z'%20/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%200V24H32V0H0Z'%20fill='%232E42A5'/%3e%3cmask%20id='mask0_270_67386'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='0'%20width='32'%20height='24'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%200V24H32V0H0Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_270_67386)'%3e%3cpath%20d='M-3.56323%2022.2854L3.47846%2025.2635L32.1597%203.23787L35.874%20-1.18761L28.344%20-2.18297L16.6456%207.3085L7.22956%2013.7035L-3.56323%2022.2854Z'%20fill='white'/%3e%3cpath%20d='M-2.59924%2024.3719L0.988173%2026.1001L34.5402%20-1.59881H29.5031L-2.59924%2024.3719Z'%20fill='%23F50100'/%3e%3cpath%20d='M35.5631%2022.2854L28.5214%2025.2635L-0.159817%203.23787L-3.87415%20-1.18761L3.65593%20-2.18297L15.3543%207.3085L24.7703%2013.7035L35.5631%2022.2854Z'%20fill='white'/%3e%3cpath%20d='M35.3229%2023.7829L31.7355%2025.5111L17.4487%2013.6518L13.2129%2012.3267L-4.23151%20-1.17246H0.805637L18.2403%2012.0063L22.8713%2013.5952L35.3229%2023.7829Z'%20fill='%23F50100'/%3e%3cmask%20id='path-7-inside-1_270_67386'%20fill='white'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M19.7777%20-2H12.2222V8H-1.97253V16H12.2222V26H19.7777V16H34.0275V8H19.7777V-2Z'/%3e%3c/mask%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M19.7777%20-2H12.2222V8H-1.97253V16H12.2222V26H19.7777V16H34.0275V8H19.7777V-2Z'%20fill='%23F50100'/%3e%3cpath%20d='M12.2222%20-2V-4H10.2222V-2H12.2222ZM19.7777%20-2H21.7777V-4H19.7777V-2ZM12.2222%208V10H14.2222V8H12.2222ZM-1.97253%208V6H-3.97253V8H-1.97253ZM-1.97253%2016H-3.97253V18H-1.97253V16ZM12.2222%2016H14.2222V14H12.2222V16ZM12.2222%2026H10.2222V28H12.2222V26ZM19.7777%2026V28H21.7777V26H19.7777ZM19.7777%2016V14H17.7777V16H19.7777ZM34.0275%2016V18H36.0275V16H34.0275ZM34.0275%208H36.0275V6H34.0275V8ZM19.7777%208H17.7777V10H19.7777V8ZM12.2222%200H19.7777V-4H12.2222V0ZM14.2222%208V-2H10.2222V8H14.2222ZM-1.97253%2010H12.2222V6H-1.97253V10ZM0.0274658%2016V8H-3.97253V16H0.0274658ZM12.2222%2014H-1.97253V18H12.2222V14ZM14.2222%2026V16H10.2222V26H14.2222ZM19.7777%2024H12.2222V28H19.7777V24ZM17.7777%2016V26H21.7777V16H17.7777ZM34.0275%2014H19.7777V18H34.0275V14ZM32.0275%208V16H36.0275V8H32.0275ZM19.7777%2010H34.0275V6H19.7777V10ZM17.7777%20-2V8H21.7777V-2H17.7777Z'%20fill='white'%20mask='url(%23path-7-inside-1_270_67386)'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_270_67386'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%2016H32V24H0V16Z'%20fill='%23FFD018'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%208H32V16H0V8Z'%20fill='%23E31D1C'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%200H32V8H0V0Z'%20fill='%23272727'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_270_67353'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M22%200H32V24H22V0Z'%20fill='%23F50100'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%200H12V24H0V0Z'%20fill='%232E42A5'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M10%200H22V24H10V0Z'%20fill='%23F7FCFF'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_270_67361'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Visuelle CAPTCHAs basierten auf einer Annahme: Bots können Bilder nicht so interpretieren wie Menschen. Eine Zeit lang stimmte das in etwa. Heute nicht mehr. Das Umgehen eines CAPTCHAs ist heute eine dokumentierte, kostengünstige Operation – zugänglich für jeden, der bereit ist, ein paar Dollar pro tausend Anfragen auszugeben. Zu verstehen, wie es geschieht und welcher Schutz wirklich standhält, ist nun die praktischere Frage.
Warum visuelle CAPTCHAs leichte Ziele sind
Traditionelle CAPTCHAs stellen eine visuelle Herausforderung: verzerrten Text lesen, alle Ampeln identifizieren, ein Puzzleteil ziehen. Die Logik war, dass Computer mehrdeutige Bilder nicht so zuverlässig interpretieren können wie Menschen. Ein Blick auf wie CAPTCHAs funktionieren auf Mechanismusebene zeigt, wo diese Annahme zusammenbricht.
Computer-Vision-Modelle erreichen heute bei vielen Bildklassifikationsaufgaben eine höhere Genauigkeit als Menschen – einschließlich der Herausforderungstypen, die in CAPTCHA-Systemen verwendet werden. Der W3C-Hinweis zur Unzugänglichkeit von CAPTCHAs hat seit 2005 auf Zuverlässigkeits- und Barrierefreiheitsprobleme bei visuellen Herausforderungen hingewiesen. Die Lücke zwischen menschlicher und maschineller Leistung bei Erkennungsaufgaben hat sich seitdem nur weiter geschlossen.
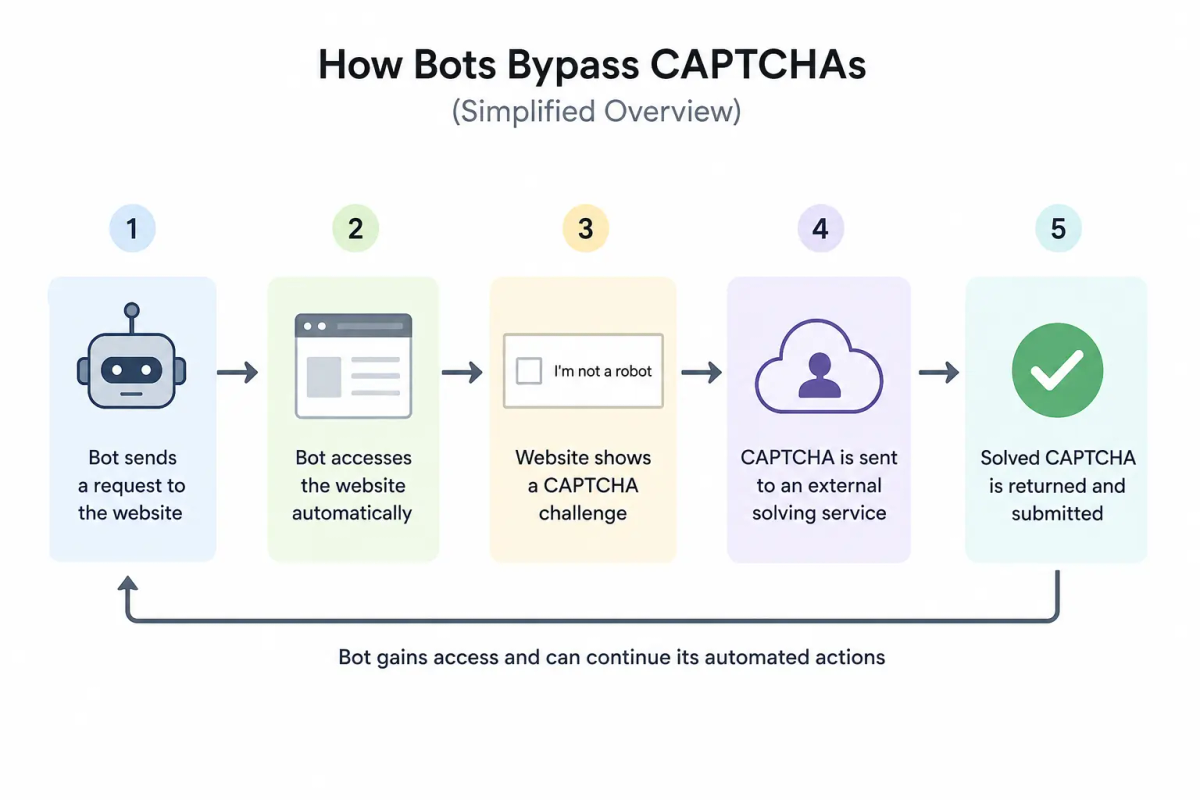
Wenn ein CAPTCHA rein auf Erkennung setzt, gibt es zwei Wege, wie ein Bot es überwinden kann: die Erkennung selbst automatisieren oder einen Menschen dafür bezahlen. Beides ist etabliert.
Wie Bots CAPTCHAs umgehen
Automatisierungs-Frameworks: Selenium, Playwright und Headless-Browser
Selenium und Playwright sind Browser-Automatisierungstools, die für das Testen von Webanwendungen entwickelt wurden. Sie steuern echte Browser – Chrome, Firefox, Edge – führen JavaScript aus, verwalten Cookies und interagieren mit Seitenelementen genauso wie ein Mensch. Wenn ein Bot über Playwright läuft, sendet er echte Browser-Header, lädt alle Seitenressourcen und feuert Klick-Events an den richtigen Koordinaten.
Ein CAPTCHA, das prüft, ob ein Nutzer eine Checkbox angeklickt hat, unterscheidet keinen menschlichen Klick von einem automatisierten. Der Browser ist echt. Die Interaktion ist echt.
Headless-Browser gehen noch weiter. Chrome Headless läuft ohne sichtbares Fenster, schneller und skalierbarer – und macht es praktikabel, Tausende automatisierter Sitzungen parallel mit minimalen Infrastrukturkosten zu betreiben.
CAPTCHA-Löserdienste
Wenn Automatisierung allein nicht ausreicht, um die visuelle Herausforderung zu interpretieren, leiten Bots sie an einen Löserdienst weiter. Zwei Hauptmodelle existieren.
Menschlich betriebene Farmen beschäftigen Mitarbeiter, die CAPTCHAs per API lösen. Der Bot übermittelt das Herausforderungsbild; ein Mitarbeiter löst es innerhalb von Sekunden; das gültige Token kommt zurück. Die Preise liegen bei etwa 1–3 USD pro tausend Lösungen. Für hochwertige Ziele – Kontoregistrierungen, Ticketkäufe, Credential-Operationen – ist dieser Preis vernachlässigbar.
KI-basierte Löser trainieren neuronale Netze auf CAPTCHA-Herausforderungsdaten. Sie laufen lokal, verursachen nur minimale Kosten pro Anfrage und bewältigen die meisten textbasierten Herausforderungen mit nahezu vollständiger Genauigkeit. Bildherausforderungen variieren je nach Typ, aber der Leistungsunterschied zu Menschen wird bei allen geringer.
Das Wettrüsten bei der Erkennung
Es gibt ein Muster darin, wie sich die Schwierigkeit von Bild-CAPTCHAs entwickelt hat: Herausforderungen werden schwieriger, Löser werden besser, und legitime Nutzer tragen den größten Teil der Reibung. Mathe-CAPTCHAs veranschaulichen diese Entwicklung gut – als sie eingeführt wurden, schienen sie eine vernünftige Vereinfachung des visuellen Herausforderungsformats zu sein. Heute werden sie von jedem grundlegenden Automatisierungsskript trivial gelöst. Komplexere Bildherausforderungen dauern länger zu überwinden, aber jede Version wird schließlich geknackt, wenn Modelle Herausforderungsdaten ansammeln.
Warum erkennungsbasierte Herausforderungen nicht standhalten
Das strukturelle Problem liegt nicht darin, dass CAPTCHA-Designer nicht clever genug sind. Es liegt daran, dass Erkennung der falsche Test ist. Jede Aufgabe, die präzise genug beschrieben werden kann, um eine Maschine darauf zu trainieren, wird schließlich automatisierbar sein. Das gilt für jede visuelle Herausforderung, die je in einem CAPTCHA eingesetzt wurde.
Herausforderungen schwieriger zu machen behebt das nicht – es verzögert es nur. Und schwierigere Herausforderungen verursachen echte Kosten für Nutzer mit visuellen oder kognitiven Einschränkungen, während Bot-Betreiber auf verbesserte Modelle warten.
Rate Limiting und IP-Blockierung bieten am Rand etwas Schutz. Bots, die durch Playwright mit menschlichem Timing laufen, umgehen einfache Rate-Trigger. Anspruchsvollere Operationen rotieren IPs über Wohn-Proxy-Netzwerke. Diese Maßnahmen reduzieren das Volumen – sie lösen nicht die Absicht dahinter.
Was wirklich funktioniert: Eine geschichtete Verteidigung
Schutz, der gegen modernen CAPTCHA-Bypass standhält, ersetzt nicht einen Erkennungstest durch einen schwereren. Er fügt eine Schicht hinzu, die überhaupt nicht von Erkennung abhängt.
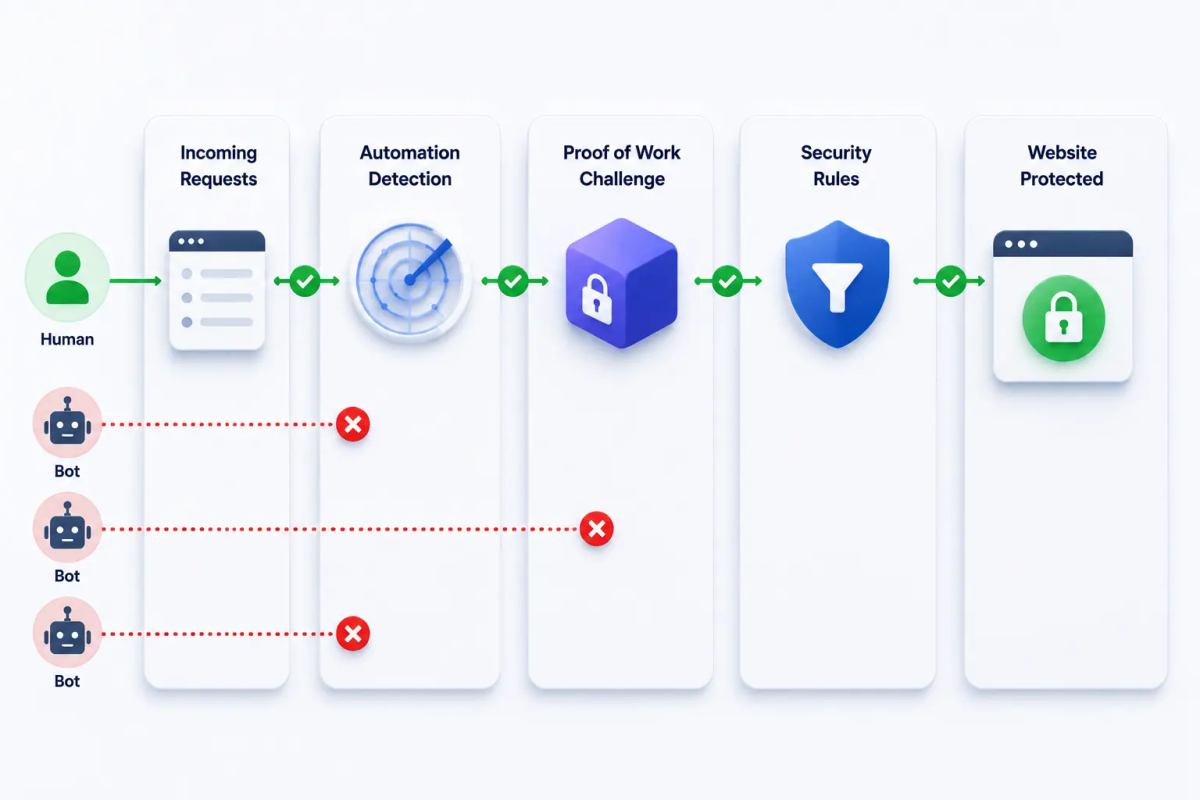
Bot-Signal-Erkennung
Browser- und Verhaltenssignale können automatisierten Traffic in vielen Fällen identifizieren. Bot-Scoring-Systeme, die diese Signale auswerten, können verdächtige Anfragen kennzeichnen, bevor überhaupt eine Herausforderung präsentiert wird.
Diese Schicht stoppt bereits einen großen Prozentsatz von Bots und Spam. Anspruchsvollere Operationen sind speziell darauf ausgelegt, an der signalbasierten Erkennung vorbeizukommen – weshalb eine zweite Schicht notwendig ist.
Proof of Work: Die Schicht, die nicht ausgelagert werden kann
Proof of Work fordert den Browser auf, etwas zu berechnen, anstatt etwas zu erkennen. Die Herausforderung ist kryptografisch – eine Hash-Berechnung, die echte CPU-Zeit erfordert. Der Browser eines legitimen Nutzers erledigt sie im Hintergrund, unsichtbar. Der Nutzer bemerkt nichts.
Für eine einzelne Anfrage sind die Kosten vernachlässigbar. Für einen Bot-Betrieb mit Tausenden gleichzeitiger Sitzungen werden die aggregierten Berechnungen real. Im Gegensatz zur Bilderkennung kann Berechnung nicht an eine menschliche Löserfarm delegiert werden – Mitarbeiter können keine Hashes lösen, nur Algorithmen können das. Und anders als bei KI-Bildlösern gibt es keine Trainingsabkürzung. Die Arbeit muss einfach stattfinden.
Wenn erhöhte Risikosignale auftreten, skaliert die Proof-of-Work-Schwierigkeit automatisch. Traffic mit niedrigem Risiko passiert schnell; verdächtiger Traffic erhält eine schwerere Herausforderung. Echte Nutzer sind nie betroffen, weil die Berechnung läuft, ohne sie zu unterbrechen.
Das ist, was Proof of Work von erkennungsbasierten Ansätzen unterscheidet: Die Kosten für den Angreifer skalieren mit dem Maßstab. Bild-CAPTCHAs werden billiger zu umgehen, wenn Modelle besser werden. Proof of Work nicht.
TrustCaptcha: Drei Schichten arbeiten zusammen
TrustCaptcha führt beide Mechanismen hintereinander aus. Jede Anfrage wird gegen Browser- und Verhaltenssignale bewertet. Für echte Nutzer läuft die Proof-of-Work-Herausforderung unsichtbar im Hintergrund. Für Anfragen mit erhöhten Risikosignalen erhöht sich die Herausforderungsschwierigkeit automatisch.
Es gibt kein Bild, das an eine Löserfarm weitergeleitet werden könnte. Es gibt keine Checkbox, durch die ein Playwright-Skript klicken könnte. Die Bot-Erkennungsfunktionen übernehmen den ersten Filter; Proof of Work übernimmt den Rest. Ein Bot, der eine Schicht umgeht, trifft immer noch auf die andere.
Darüber hinaus unterstützt TrustCaptcha benutzerdefinierte Sicherheitsregeln – die es Website-Betreibern ermöglichen, granulare, situationsspezifische Bedingungen zu definieren, die zusätzliche Maßnahmen auslösen. Regeln können auf bestimmte Endpunkte, Traffic-Muster oder Risikoschwellen abzielen und Teams direkte Kontrolle darüber geben, wie sich der Schutz in ihrem spezifischen Kontext verhält, ohne ausschließlich auf automatisches Scoring angewiesen zu sein.
Für Websites, die moderne CAPTCHA-Alternativen ohne Google-Abhängigkeit oder DSGVO-Risiken evaluieren, läuft TrustCaptcha auf ausschließlich EU-Infrastruktur und speichert keine Cookies. Ein Auftragsverarbeitungsvertrag (AVV) ist in jedem Plan enthalten – keine separaten rechtlichen Verhandlungen erforderlich.
Fazit
- Visuelle CAPTCHAs können zuverlässig mit Browser-Automatisierungs-Frameworks wie Selenium oder Playwright umgangen werden, oder durch CAPTCHA-Löserdienste zu Preisen unter 3 USD pro tausend Herausforderungen.
- Bildherausforderungen schwieriger zu machen betrifft hauptsächlich legitime Nutzer. Es behebt das zugrundeliegende Problem nicht, dass Erkennungsaufgaben zunehmend automatisierbar sind.
- Bot-Signal-Erkennung stoppt bereits einen großen Prozentsatz von Bots und Spam. Anspruchsvollere Operationen sind darauf ausgelegt, daran vorbeizukommen – weshalb eine zweite Schicht notwendig ist.
- Proof of Work ist die Schicht, die standhält, wenn die Erkennung versagt. Es erfordert echte Berechnungen, die nicht an Menschen ausgelagert oder durch KI beschleunigt werden können.
- Ein CAPTCHA wie TrustCaptcha, das Bot-Signal-Erkennung, Proof of Work und benutzerdefinierte Sicherheitsregeln kombiniert, kann Bypass-Versuche zuverlässig blockieren – unabhängig davon, ob der Angriff auf Automatisierung, Löserdiensten oder fortgeschrittener Umgehung basiert, trifft er auf mindestens eine Schicht.
TrustCaptcha kostenlos testen
Ihre Nutzer sollten keine Rätsel lösen müssen, um zu beweisen, dass sie Menschen sind – und Sie sollten nicht zwischen einer reibungslosen Erfahrung und zuverlässigem Schutz wählen müssen. TrustCaptcha kostenlos testen: unsichtbare Verifikation, die echte Nutzer nie bemerken, keine Interaktion erforderlich und Bot-Schutz, der modernen Bypass-Versuchen standhält.