%20--%3e%3csvg%20version='1.1'%20xmlns='http://www.w3.org/2000/svg'%20x='0px'%20y='0px'%20viewBox='0%200%20207.3%2029'%20style='enable-background:new%200%200%20207.3%2029;'%20xml:space='preserve'%3e%3cstyle%20type='text/css'%3e%20.st0{fill:%231E293B;}%20.st1{fill:%232563eb;}%20%3c/style%3e%3cg%20id='Ebene_1'%3e%3cg%20id='Ebene_2_00000023959154727838081460000010218683892316788135_'%3e%3cg%3e%3cg%3e%3cpath%20class='st0'%20d='M24.3,7.4c0-0.8,0-1.5,0-2.2c0-0.6-0.4-1-1-1c-4.4,0-7.6-1.2-10.4-3.9c-0.4-0.3-1-0.3-1.5,0%20C8.7,2.9,5.4,4.1,1.1,4.1c-0.6,0-1,0.5-1,1c0,0.7,0,1.5,0,2.2c-0.2,7.4-0.4,17.3,11.8,21.6l0.3,0.1l0.3-0.1%20C24.6,24.6,24.4,14.7,24.3,7.4z%20M11.4,17.5C11.4,17.5,11.3,17.5,11.4,17.5c-0.3,0.2-0.5,0.3-0.8,0.3l0,0c-0.3,0-0.5-0.2-0.7-0.3%20l-2.7-3c-0.3-0.3-0.3-0.9,0.1-1.1L7.5,13c0.3-0.3,0.9-0.3,1.1,0.1l1.4,1.6c0.3,0.3,0.8,0.3,1.1,0.1l4.4-4.2%20c0.3-0.3,0.9-0.3,1.1,0l0.3,0.3c0.3,0.3,0.3,0.9,0,1.1L11.4,17.5z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg%20id='Ebene_2'%3e%3cg%3e%3cpath%20class='st1'%20d='M46.3,8.6h-5.1v14.1h-2.8V8.6h-5.1V6.2h13V8.6z'/%3e%3cpath%20class='st1'%20d='M54.3,16.2h-3.2v6.3h-2.8V6.2h5.8c1.9,0,3.3,0.4,4.4,1.3S60,9.6,60,11.2c0,1.1-0.3,2-0.8,2.8%20c-0.5,0.7-1.3,1.3-2.2,1.7l3.7,6.8v0.2h-3L54.3,16.2z%20M51.1,13.9H54c1,0,1.7-0.2,2.2-0.7s0.8-1.1,0.8-2s-0.2-1.5-0.8-2%20C55.7,8.7,55,8.5,54,8.5h-3v5.4H51.1z'/%3e%3cpath%20class='st1'%20d='M74.3,6.2v10.9c0,1.7-0.6,3.1-1.7,4.1s-2.6,1.5-4.4,1.5c-1.9,0-3.4-0.5-4.5-1.5c-1.1-1-1.6-2.3-1.6-4.1V6.2%20h2.8v10.9c0,1.1,0.3,1.9,0.8,2.5c0.5,0.6,1.4,0.9,2.5,0.9c2.2,0,3.3-1.1,3.3-3.5V6.2H74.3z'/%3e%3cpath%20class='st1'%20d='M85.7,18.3c0-0.7-0.2-1.3-0.8-1.7c-0.5-0.4-1.4-0.8-2.7-1.2c-1.3-0.4-2.4-0.8-3.1-1.3%20c-1.5-0.9-2.2-2.2-2.2-3.7c0-1.3,0.5-2.4,1.6-3.3s2.5-1.3,4.2-1.3c1.1,0,2.2,0.2,3,0.6c0.8,0.4,1.6,1,2.1,1.8s0.8,1.6,0.8,2.6%20h-2.8c0-0.9-0.3-1.5-0.8-2s-1.3-0.7-2.3-0.7c-0.9,0-1.7,0.2-2.2,0.6s-0.8,1-0.8,1.7c0,0.6,0.3,1.1,0.8,1.5s1.5,0.8,2.7,1.2%20c1.2,0.4,2.3,0.8,3.1,1.3c0.8,0.5,1.3,1,1.7,1.7c0.4,0.6,0.5,1.4,0.5,2.2c0,1.4-0.5,2.5-1.6,3.2c-1,0.8-2.5,1.2-4.2,1.2%20c-1.2,0-2.3-0.2-3.3-0.7c-1-0.4-1.8-1-2.3-1.8s-0.8-1.7-0.8-2.7h2.8c0,0.9,0.3,1.6,0.9,2.2c0.6,0.6,1.5,0.8,2.6,0.8%20c1,0,1.7-0.2,2.2-0.6C85.4,19.5,85.7,19,85.7,18.3z'/%3e%3cpath%20class='st1'%20d='M102.6,8.6h-5.1v14.1h-2.8V8.6h-5.1V6.2h13V8.6z'/%3e%3cpath%20class='st0'%20d='M117,17.2c-0.2,1.7-0.8,3.1-1.9,4.1s-2.6,1.5-4.5,1.5c-1.3,0-2.4-0.3-3.4-0.9c-1-0.6-1.8-1.5-2.3-2.6%20c-0.5-1.1-0.8-2.5-0.8-4v-1.5c0-1.5,0.3-2.9,0.8-4.1s1.3-2.1,2.3-2.7s2.2-0.9,3.5-0.9c1.8,0,3.3,0.5,4.4,1.5s1.7,2.4,1.9,4.1h-2.8%20c-0.1-1.2-0.5-2-1-2.5c-0.6-0.5-1.4-0.8-2.4-0.8c-1.2,0-2.2,0.5-2.8,1.4c-0.7,0.9-1,2.2-1,4v1.5c0,1.8,0.3,3.1,0.9,4.1%20s1.6,1.4,2.8,1.4c1.1,0,1.9-0.2,2.5-0.8c0.6-0.5,0.9-1.3,1.1-2.5L117,17.2L117,17.2z'/%3e%3cpath%20class='st0'%20d='M128.5,18.8h-6.4l-1.3,3.8h-2.9l6.2-16.4h2.6l6.2,16.4h-3L128.5,18.8z%20M122.9,16.5h4.7l-2.4-6.8L122.9,16.5z'%20/%3e%3cpath%20class='st0'%20d='M137.2,16.5v6.1h-2.8V6.2h6.3c1.8,0,3.3,0.5,4.3,1.4c1.1,1,1.6,2.2,1.6,3.8c0,1.6-0.5,2.9-1.6,3.7%20c-1.1,0.8-2.5,1.3-4.4,1.3C140.6,16.4,137.2,16.4,137.2,16.5z%20M137.2,14.2h3.4c1,0,1.8-0.2,2.3-0.7s0.8-1.2,0.8-2.1%20s-0.3-1.6-0.8-2.1s-1.3-0.8-2.2-0.8h-3.5C137.2,8.6,137.2,14.2,137.2,14.2z'/%3e%3cpath%20class='st0'%20d='M160.7,8.6h-5.1v14.1h-2.8V8.6h-5.1V6.2h13V8.6L160.7,8.6z'/%3e%3cpath%20class='st0'%20d='M175.1,17.2c-0.2,1.7-0.8,3.1-1.9,4.1c-1.1,1-2.6,1.5-4.5,1.5c-1.3,0-2.4-0.3-3.4-0.9c-1-0.6-1.8-1.5-2.3-2.6%20c-0.5-1.1-0.8-2.5-0.8-4v-1.5c0-1.5,0.3-2.9,0.8-4.1s1.3-2.1,2.4-2.7c1-0.6,2.2-0.9,3.5-0.9c1.8,0,3.3,0.5,4.4,1.5%20s1.7,2.4,1.9,4.1h-2.8c-0.1-1.2-0.5-2-1-2.5S170,8.4,169,8.4c-1.2,0-2.2,0.5-2.9,1.4s-1,2.2-1,4v1.5c0,1.8,0.3,3.1,0.9,4.1%20c0.6,0.9,1.6,1.4,2.8,1.4c1.1,0,1.9-0.2,2.5-0.8c0.6-0.5,0.9-1.3,1.1-2.5L175.1,17.2L175.1,17.2z'/%3e%3cpath%20class='st0'%20d='M190.4,22.5h-2.8v-7.2h-7.3v7.2h-2.8V6.2h2.8v6.8h7.3V6.2h2.8V22.5z'/%3e%3cpath%20class='st0'%20d='M202.8,18.8h-6.3l-1.3,3.8h-2.9l6.2-16.4h2.6l6.2,16.4h-3L202.8,18.8z%20M197.3,16.5h4.7l-2.4-6.8L197.3,16.5z'%20/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%200V24H32V0H0Z'%20fill='%232E42A5'/%3e%3cmask%20id='mask0_270_67386'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='0'%20width='32'%20height='24'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%200V24H32V0H0Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_270_67386)'%3e%3cpath%20d='M-3.56323%2022.2854L3.47846%2025.2635L32.1597%203.23787L35.874%20-1.18761L28.344%20-2.18297L16.6456%207.3085L7.22956%2013.7035L-3.56323%2022.2854Z'%20fill='white'/%3e%3cpath%20d='M-2.59924%2024.3719L0.988173%2026.1001L34.5402%20-1.59881H29.5031L-2.59924%2024.3719Z'%20fill='%23F50100'/%3e%3cpath%20d='M35.5631%2022.2854L28.5214%2025.2635L-0.159817%203.23787L-3.87415%20-1.18761L3.65593%20-2.18297L15.3543%207.3085L24.7703%2013.7035L35.5631%2022.2854Z'%20fill='white'/%3e%3cpath%20d='M35.3229%2023.7829L31.7355%2025.5111L17.4487%2013.6518L13.2129%2012.3267L-4.23151%20-1.17246H0.805637L18.2403%2012.0063L22.8713%2013.5952L35.3229%2023.7829Z'%20fill='%23F50100'/%3e%3cmask%20id='path-7-inside-1_270_67386'%20fill='white'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M19.7777%20-2H12.2222V8H-1.97253V16H12.2222V26H19.7777V16H34.0275V8H19.7777V-2Z'/%3e%3c/mask%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M19.7777%20-2H12.2222V8H-1.97253V16H12.2222V26H19.7777V16H34.0275V8H19.7777V-2Z'%20fill='%23F50100'/%3e%3cpath%20d='M12.2222%20-2V-4H10.2222V-2H12.2222ZM19.7777%20-2H21.7777V-4H19.7777V-2ZM12.2222%208V10H14.2222V8H12.2222ZM-1.97253%208V6H-3.97253V8H-1.97253ZM-1.97253%2016H-3.97253V18H-1.97253V16ZM12.2222%2016H14.2222V14H12.2222V16ZM12.2222%2026H10.2222V28H12.2222V26ZM19.7777%2026V28H21.7777V26H19.7777ZM19.7777%2016V14H17.7777V16H19.7777ZM34.0275%2016V18H36.0275V16H34.0275ZM34.0275%208H36.0275V6H34.0275V8ZM19.7777%208H17.7777V10H19.7777V8ZM12.2222%200H19.7777V-4H12.2222V0ZM14.2222%208V-2H10.2222V8H14.2222ZM-1.97253%2010H12.2222V6H-1.97253V10ZM0.0274658%2016V8H-3.97253V16H0.0274658ZM12.2222%2014H-1.97253V18H12.2222V14ZM14.2222%2026V16H10.2222V26H14.2222ZM19.7777%2024H12.2222V28H19.7777V24ZM17.7777%2016V26H21.7777V16H17.7777ZM34.0275%2014H19.7777V18H34.0275V14ZM32.0275%208V16H36.0275V8H32.0275ZM19.7777%2010H34.0275V6H19.7777V10ZM17.7777%20-2V8H21.7777V-2H17.7777Z'%20fill='white'%20mask='url(%23path-7-inside-1_270_67386)'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_270_67386'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%2016H32V24H0V16Z'%20fill='%23FFD018'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%208H32V16H0V8Z'%20fill='%23E31D1C'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%200H32V8H0V0Z'%20fill='%23272727'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_270_67353'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M22%200H32V24H22V0Z'%20fill='%23F50100'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%200H12V24H0V0Z'%20fill='%232E42A5'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M10%200H22V24H10V0Z'%20fill='%23F7FCFF'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_270_67361'%3e%3crect%20width='32'%20height='24'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Les CAPTCHAs visuels reposaient sur une hypothèse : les bots ne peuvent pas interpréter les images comme le font les humains. Pendant un temps, c’était à peu près vrai. Ce n’est plus le cas. Aujourd’hui, contourner un CAPTCHA est une opération documentée et peu coûteuse — accessible à quiconque accepte de dépenser quelques dollars par millier de requêtes. Comprendre comment cela se produit et quelle protection tient réellement est désormais la question la plus utile.
Pourquoi les CAPTCHAs visuels sont des cibles faciles
Les CAPTCHAs traditionnels présentent un défi visuel : lire du texte déformé, identifier tous les feux de circulation, faire glisser une pièce de puzzle. La logique était que les ordinateurs ne pouvaient pas interpréter de manière fiable des images ambiguës comme les humains. Comprendre comment fonctionnent les CAPTCHAs au niveau mécanistique montre où cette hypothèse s’effondre.
Les modèles de vision par ordinateur atteignent désormais une précision supérieure à celle des humains sur de nombreuses tâches de classification d’images, y compris les types de défis utilisés dans les systèmes CAPTCHA. La note du W3C sur l’inaccessibilité des CAPTCHAs signale des problèmes de fiabilité et d’accessibilité avec les défis visuels depuis 2005. L’écart entre les performances humaines et machines sur les tâches de reconnaissance n’a fait que se réduire depuis.
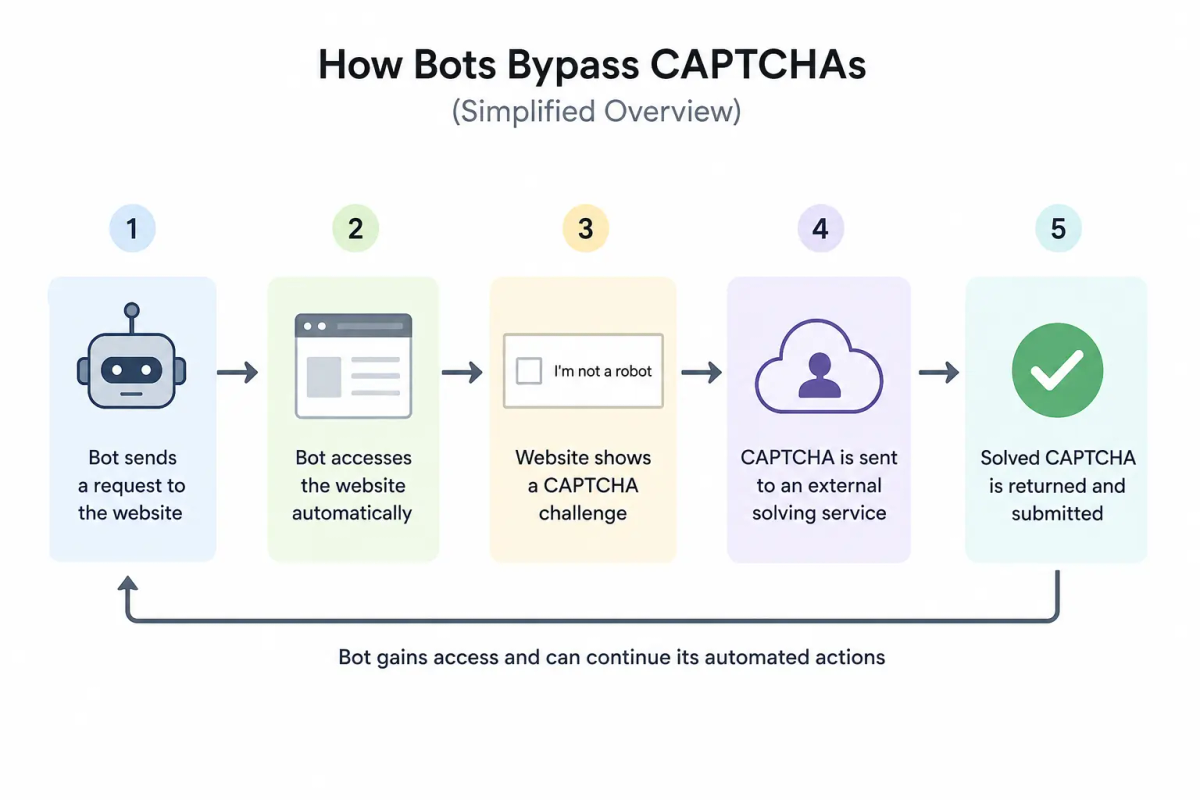
Lorsqu’un CAPTCHA repose uniquement sur la reconnaissance, il existe deux façons pour un bot de le contourner : automatiser la reconnaissance elle-même, ou payer un humain pour le faire. Les deux sont bien établis.
Comment les bots contournent les CAPTCHAs
Frameworks d’automatisation : Selenium, Playwright et navigateurs headless
Selenium et Playwright sont des outils d’automatisation de navigateur conçus pour tester des applications web. Ils contrôlent de vrais navigateurs — Chrome, Firefox, Edge — exécutent JavaScript, gèrent les cookies et interagissent avec les éléments de page exactement comme un humain le ferait. Lorsqu’un bot passe par Playwright, il envoie de vrais en-têtes de navigateur, charge toutes les ressources de la page et déclenche des événements de clic aux bonnes coordonnées.
Un CAPTCHA qui vérifie si un utilisateur a cliqué sur une case ne distingue pas un clic humain d’un clic automatisé. Le navigateur est réel. L’interaction est réelle.
Les navigateurs headless vont encore plus loin. Chrome Headless fonctionne sans fenêtre visible, plus rapide et plus évolutif — rendant pratique l’exécution de milliers de sessions automatisées en parallèle avec des coûts d’infrastructure minimaux.
Services de résolution de CAPTCHA
Lorsque l’automatisation seule ne suffit pas pour interpréter le défi visuel, les bots le routent vers un service de résolution. Deux modèles principaux existent.
Les fermes à base humaine emploient des travailleurs pour résoudre les CAPTCHAs via API. Le bot soumet l’image du défi ; un travailleur la résout en quelques secondes ; le jeton valide revient. Les prix s’élèvent à environ 1 à 3 dollars par millier de solutions. Pour les cibles à haute valeur — inscriptions de comptes, achats de billets, opérations d’identifiants — ce coût est négligeable.
Les solveurs basés sur l’IA entraînent des réseaux de neurones sur des données de défis CAPTCHA. Ils fonctionnent localement, n’engendrent qu’un coût minimal par requête, et traitent la plupart des défis textuels avec une précision quasi complète. Les défis visuels varient selon le type, mais l’écart de performance avec les humains se réduit pour tous.
La course aux armements de la reconnaissance
Il existe un schéma dans l’évolution de la difficulté des CAPTCHAs visuels : les défis deviennent plus difficiles, les solveurs s’améliorent, et les utilisateurs légitimes absorbent la plupart des frictions. Les CAPTCHAs mathématiques illustrent bien cette trajectoire — lorsqu’ils ont été introduits, ils semblaient être une simplification raisonnable du format de défi visuel. Aujourd’hui, ils sont trivialement résolus par n’importe quel script d’automatisation basique. Les défis visuels plus complexes prennent plus de temps à surmonter, mais chaque version finit par être vaincue à mesure que les modèles accumulent des données de défis.
Pourquoi les défis basés sur la reconnaissance ne tiennent pas
Le problème structurel n’est pas que les concepteurs de CAPTCHA ne sont pas assez intelligents. C’est que la reconnaissance est le mauvais test. Toute tâche qui peut être décrite assez précisément pour entraîner une machine finira par être automatisable. Cela s’applique à chaque défi visuel jamais déployé dans un CAPTCHA.
Rendre les défis plus difficiles ne règle pas ce problème — cela le retarde. Et des défis plus difficiles imposent des coûts réels aux utilisateurs souffrant de handicaps visuels ou cognitifs, tandis que les opérateurs de bots attendent des modèles améliorés.
La limitation de débit et le blocage d’IP offrent une certaine protection en marge. Les bots passant par Playwright à un rythme humain évitent les déclencheurs de débit simples. Les opérations sophistiquées font tourner les IPs sur des réseaux de proxies résidentiels. Ces mesures réduisent le volume — elles ne résolvent pas l’intention.
Ce qui fonctionne vraiment : une défense en couches
Une protection qui tient face au contournement moderne de CAPTCHA ne remplace pas un test de reconnaissance par un plus difficile. Elle ajoute une couche qui ne dépend pas du tout de la reconnaissance.
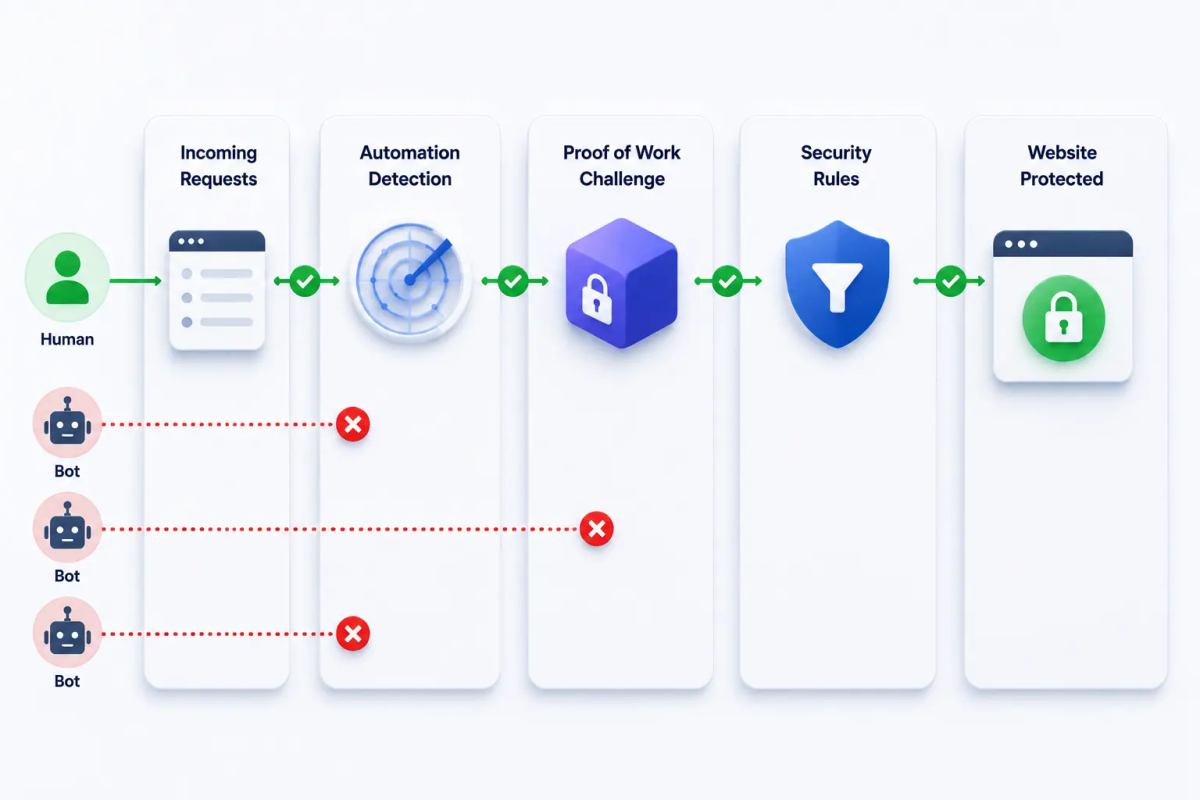
Détection de signaux de bots
Les signaux du navigateur et du comportement peuvent identifier le trafic automatisé dans de nombreux cas. Les systèmes de scoring de bots qui évaluent ces signaux peuvent signaler les requêtes suspectes avant même qu’un défi soit présenté.
Cette couche arrête déjà un grand pourcentage de bots et de spam. Les opérations plus sophistiquées sont spécifiquement conçues pour passer inaperçues face à la détection basée sur les signaux — c’est pourquoi une seconde couche est nécessaire.
Preuve de travail : la couche qui ne peut pas être sous-traitée
La preuve de travail demande au navigateur de calculer quelque chose plutôt que de reconnaître quelque chose. Le défi est cryptographique — un calcul de hachage qui nécessite du temps CPU réel. Le navigateur d’un utilisateur légitime le complète en arrière-plan, de manière invisible. L’utilisateur ne remarque rien.
Pour une seule requête, le coût est négligeable. Pour une opération de bot exécutant des milliers de sessions simultanées, le calcul cumulé devient réel. Contrairement à la reconnaissance d’images, le calcul ne peut pas être délégué à une ferme de résolution humaine — les travailleurs ne peuvent pas résoudre des hachages, seuls les algorithmes le peuvent. Et contrairement aux solveurs d’images IA, il n’existe pas de raccourci d’entraînement. Le travail doit simplement avoir lieu.
Lorsque des signaux de risque élevés apparaissent, la difficulté de la preuve de travail monte automatiquement. Le trafic à faible risque passe rapidement ; le trafic suspect reçoit un défi plus difficile. Les vrais utilisateurs ne sont jamais affectés car le calcul s’exécute sans les interrompre.
C’est ce qui distingue la preuve de travail des approches basées sur la reconnaissance : le coût pour l’attaquant évolue avec l’échelle. Les CAPTCHAs visuels deviennent moins coûteux à contourner à mesure que les modèles s’améliorent. La preuve de travail, non.
TrustCaptcha : trois couches travaillant ensemble
TrustCaptcha exécute les deux mécanismes en séquence. Chaque requête est évaluée par rapport aux signaux du navigateur et du comportement. Pour les vrais utilisateurs, le défi de preuve de travail s’exécute invisiblement en arrière-plan. Pour les requêtes présentant des signaux de risque élevés, la difficulté du défi augmente automatiquement.
Il n’y a pas d’image à router vers une ferme de résolution. Il n’y a pas de case qu’un script Playwright peut cocher. Les fonctionnalités de détection de bots gèrent le premier filtre ; la preuve de travail gère le reste. Un bot qui esquive une couche en heurte quand même une autre.
En plus de ces deux couches, TrustCaptcha prend en charge des règles de sécurité personnalisées — permettant aux opérateurs de site de définir des conditions granulaires et spécifiques à la situation qui déclenchent des actions supplémentaires. Les règles peuvent cibler des endpoints spécifiques, des patterns de trafic ou des seuils de risque, donnant aux équipes un contrôle direct sur le comportement de la protection dans leur contexte particulier sans dépendre uniquement du scoring automatisé.
Pour les sites évaluant des alternatives modernes au CAPTCHA sans dépendance à Google ou exposition au RGPD, TrustCaptcha fonctionne sur une infrastructure exclusivement européenne et ne stocke aucun cookie. Un accord de traitement des données est inclus avec chaque abonnement — aucune négociation juridique séparée requise.
Points clés à retenir
- Les CAPTCHAs visuels peuvent être contournés de manière fiable à l’aide de frameworks d’automatisation de navigateur comme Selenium ou Playwright, ou via des services de résolution de CAPTCHA à moins de 3 dollars par millier de défis.
- Rendre les défis visuels plus difficiles pénalise principalement les utilisateurs légitimes. Cela ne règle pas le problème sous-jacent que les tâches de reconnaissance sont de plus en plus automatisables.
- La détection de signaux de bots arrête déjà un grand pourcentage de bots et de spam. Les opérations plus sophistiquées sont conçues pour la contourner — rendant une seconde couche nécessaire.
- La preuve de travail est la couche qui tient quand la détection échoue. Elle nécessite un calcul réel qui ne peut pas être sous-traité à des humains ni résolu plus rapidement par l’IA.
- Un CAPTCHA comme TrustCaptcha qui combine détection de signaux de bots, preuve de travail et règles de sécurité personnalisées peut bloquer de manière fiable les tentatives de contournement — que l’attaque repose sur l’automatisation, les services de résolution ou l’évasion avancée, au moins une couche s’applique.
Essayez TrustCaptcha gratuitement
Vos utilisateurs ne devraient pas avoir à résoudre des puzzles pour prouver qu’ils sont humains — et vous ne devriez pas avoir à choisir entre une expérience fluide et une protection fiable. Essayez TrustCaptcha gratuitement : une vérification invisible que les vrais utilisateurs ne remarquent jamais, sans interaction requise, et une protection contre les bots qui résiste aux tentatives de contournement modernes.